
저장 프로시저
저장 프로시저는 데이터베이스 시스템에서 실행을 위해 미리 컴파일하고 저장해둔 쿼리의 집합이며, 여러 명령문을 하나의 로직으로 묶어서 관리한다.
프로시저를 만들어두면, 쿼리가 필요할 때 인자 값만 전달하면 된다.
SQL 예시 코드
CREATE PROCEDURE GetEmployeeByID
@EmpID INT
AS
BEGIN
SELECT * FROM Employees WHERE EmployeeID = @EmpID;
END
// 호출
EXECUTE GetEmployeeByID @EmpID = 123;MySQL 예시 코드
CREATE PROCEDURE `GetEmployeeByID`(IN `empID` INT)
BEGIN
SELECT * FROM Employees WHERE EmployeeID = empID;
END
// 호출
CALL GetEmployeeByID(123);
저장 프로시저의 동작방식
일반 SQL 동작방식
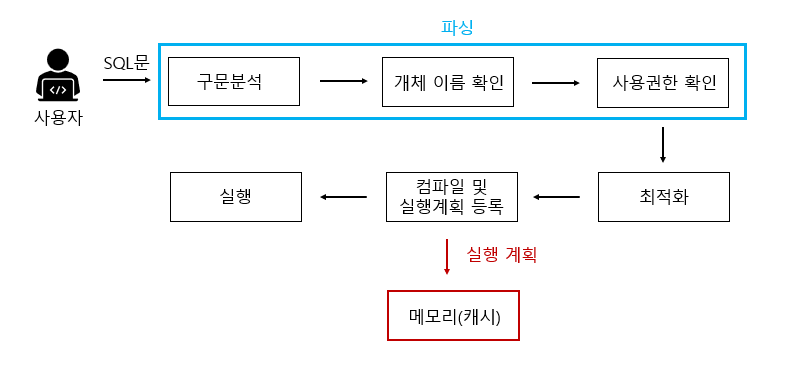
실행 과정 : 파싱 → 최적화 → 컴파일 및 실행계획 등록(실행계획 결과 메모리에 등록) → 실행
만약 같은 쿼리를 다시 실행하면 캐시에 해당 쿼리에 대한 결과가 있는지 확인하고 실행한다. (단, 쿼리가 한 글자라도 달라지면 파싱 부터 다시 동작한다.)
저장 프로시저 동작방식
1. 저장 프로시저 정의 단계
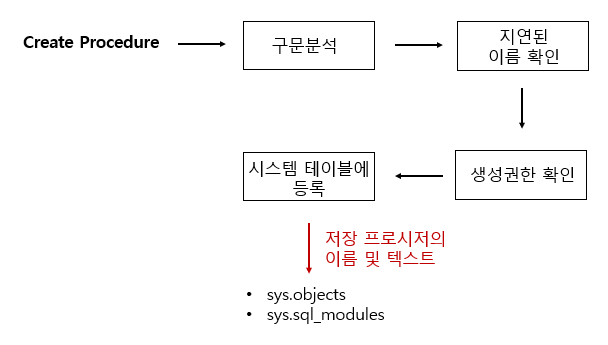
- 구문분석 : 구문의 오류 파악. 만약 문법적 오류가 있다면 저장 프로시저는 생성되지 않는다.
- 지연된 이름 확인 : 저장 프로시저가 참조하는 테이블 이름이나 필드 이름이 실제로 데이터베이스에 존재하는지 확인하는 과정. 지연된 이름 확인인 이유는 저장 프로시저가 실행될 때까지 실제로 확인되지 않기 때문이다. 이것은 저장 프로시저가 생성 시점에는 필요한 모든 테이블이나 필드가 아직 생성되지 않을 수 있음을 고려한 설계이다.
- 생성권한 확인 : 저장 프로시저를 생성하는 사용자가 해당 작업을 수행할 권한이 있는지를 확인하는 단계이다. 만약 사용자가 권한이 없다면, 저장 프로시저는 생성되지 않는다.
- 시스템 테이블 등록 : 저장 프로시저가 성공적으로 생성되면, 내용이 데이터베이스의 시스템 테이블에 등록된다. 이 테이블은 데이터베이스가 저장 프로시저를 관리하기 위해 내부적으로 사용하는 것이다.
2. 처음으로 저장 프로시저 실행
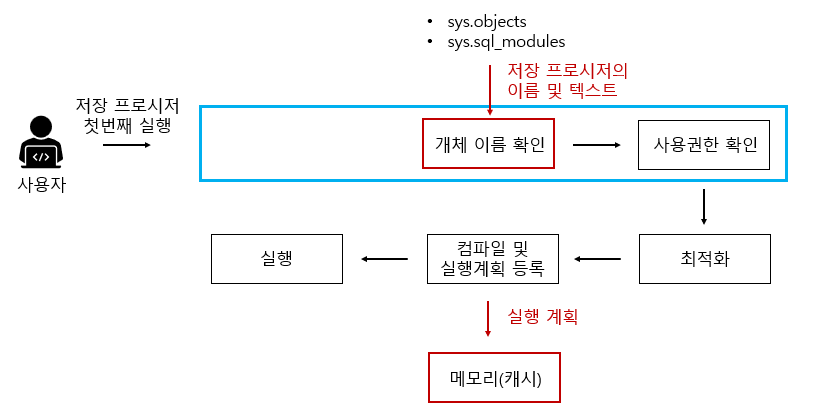
구문분석 단계가 빠지는 것만 제외하면 일반적인 쿼리문 수행단계와 동일하다. 저장 프로시저 정의 단계의 지연된 이름 확인에서 하지 않았던 개체 존재를 개체 이름 확인을 통해 수행한다.
3. 이후의 저장 프로시저 실행
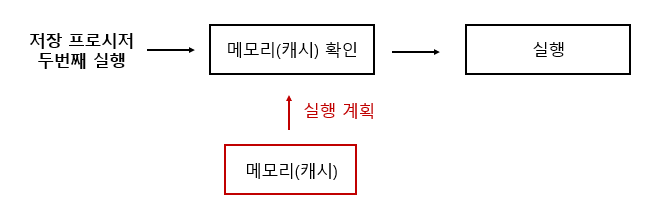
이후의 실행 부터는 메모리(캐시)에 있는 것을 가져와 재사용하게 되어 수행시간을 많이 단축한다.
저장 프로시저 장점 & 단점
장점
- 성능 향상: 저장 프로시저는 처음 실행될 때 컴파일되고 그 결과가 데이터베이스 서버에 캐시되므로, 같은 프로시저가 재실행될 경우 그 오버헤드를 피할 수 있다.
- 네트워크 트래픽 감소: 한 번의 요청으로 여러 작업을 수행할 수 있으므로 네트워크 부하를 줄일 수 있다.
- 코드 재사용과 일관성: 같은 작업을 여러 곳에서 수행해야 하는 경우 저장 프로시저를 사용하면 코드의 일관성을 유지하고 재사용성을 높일 수 있다.
- 보안 강화: 사용자별로 테이블에 권한을 주는게 아니라 저장 프로시저에만 접근 권한을 주기때문에 테이블의 모든 정보를 사용자에게 노출하지 않고 프로시저에서 선택한 정보만 사용자에게 보여줄 수 있다.
단점
- 유연성의 한계: SQL 명령문을 동적으로 생성하여 실행하는 것에 비해 저장 프로시저는 유연성이 떨어진다. 그래서 복잡한 조건이나 동적인 쿼리를 생성해야 하는 경우에는 적합하지 않을 수 있다.
- 디버깅의 어려움: 일반적인 프로그래밍 언어에 비해 저장 프로시저는 디버깅이 어렵다. 많은 데이터베이스 시스템이 저장 프로시저를 위한 특화된 디버깅 도구를 제공하지 않는다.
- 이식성 문제: 저장 프로시저는 데이터베이스 제품마다 사용 방법이 다르므로, 데이터베이스 시스템 간에 이식성이 떨어진다. 같은 로직의 저장 프로시저를 다른 시스템으로 옮기려면 새로 작성해야 할 수도 있다.
'Computer Science > Database' 카테고리의 다른 글
| [Database] 레디스 (Redis) (0) | 2023.07.16 |
|---|---|
| [Database] 트랜잭션 격리 수준 (Transaction Isolation Level) (0) | 2023.07.16 |
| [Database] 트랜잭션 (Transaction) (0) | 2023.07.07 |
| [Database] 정규화 (Normalization) (0) | 2023.07.07 |
| [Database] 인덱스 (Index) (0) | 2023.06.30 |